Open Ethics Data Passport
About
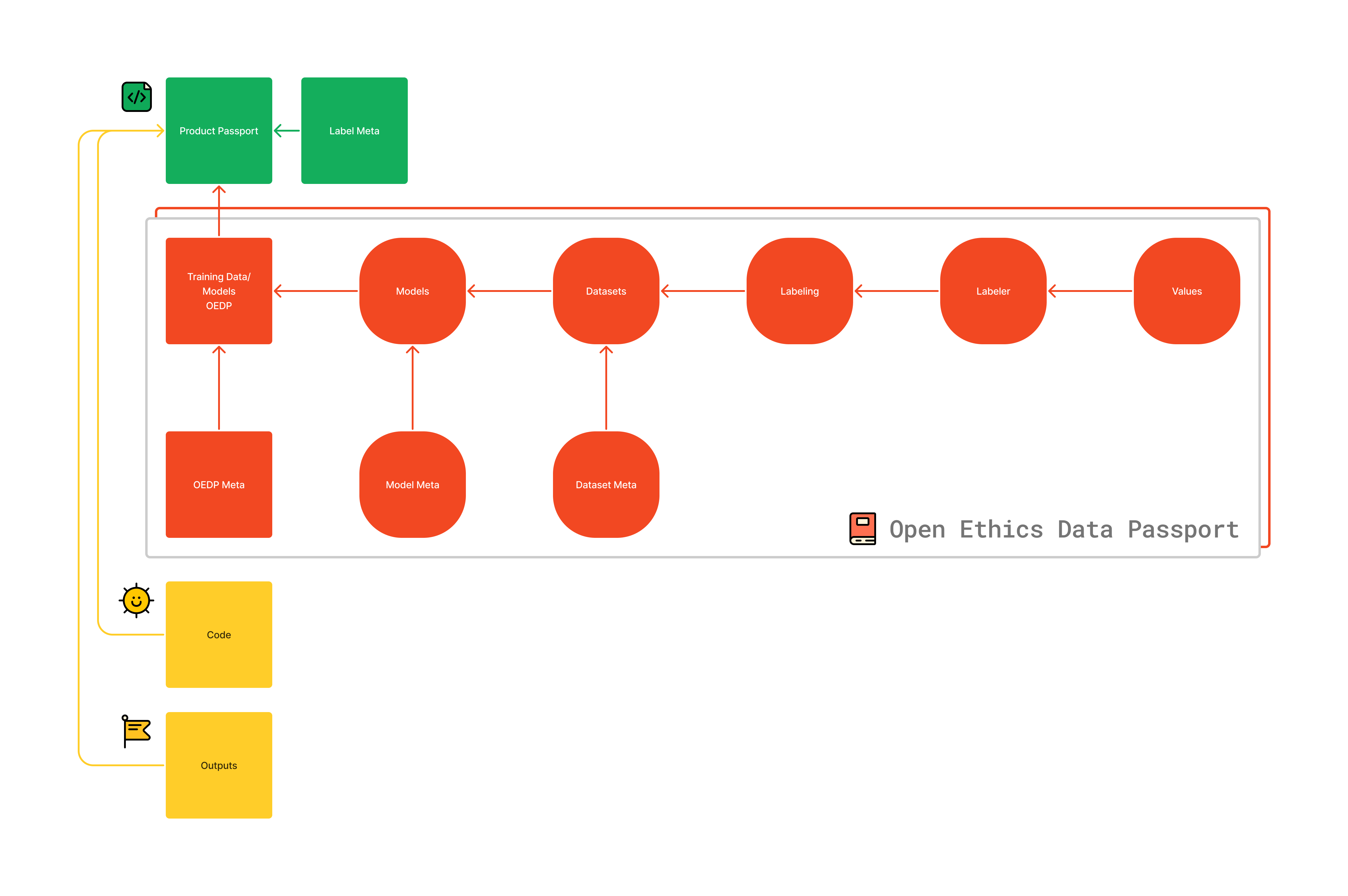
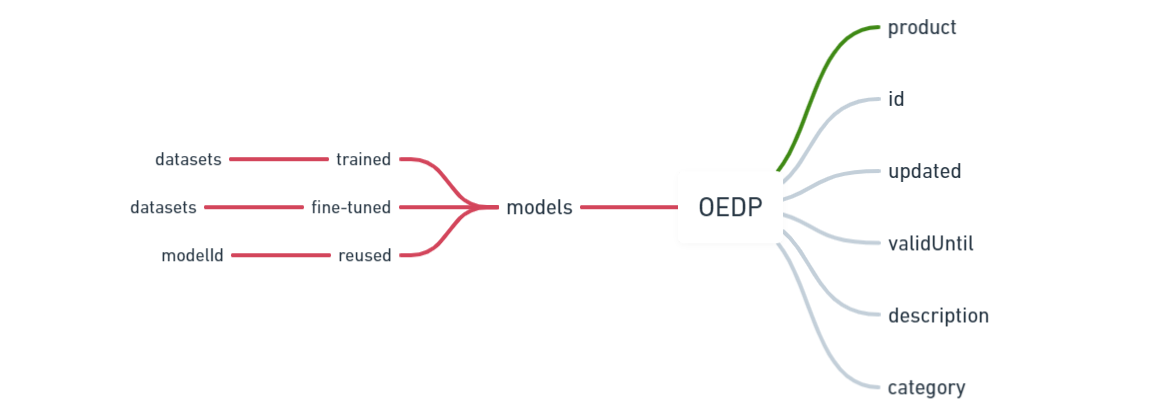
Open Ethics Data Passport (OEDP) is one of the three key parts of the disclosure for the digital product or service, alongside Decision Space and Algorithmic Transparency. OEDP is focused on describing the origins of the models by sheding light on how the training datasets were collected, cleaned, labeled, and used for training of the AI models. The main element of the OEDP is an AI model, each described with corresponding metainformation and training datasets.
Problem
Supervised learning remains one of the most widely used approaches in machine learning. A supervised learning approach requires data annotated by subject-matter experts to train machine learning algorithms. Part of the bias and algorithmic unfairness gets inherited from the historically labeled data. It is a socio-technological phenomenon that happens because people who label the data or the ones who make decisions mapping inputs to outputs unconsciously carry biases already (we are humans). Transparency around who labeled the data and the impact of the profile of the data labeler – their expertise, their personality, and their value hierarchies on the resulting fairness and accuracy properties of the machine learning models remain unknown.
Unsupervised learning can inherit bias from training data that doesn’t represent the real world or contains prejudices. For instance, if a clustering algorithm trains on data disproportionately favoring one group, it can create biased clusters. This issue is notable in generative AI like large language models (LLMs), trained on vast, unlabeled text corpora, potentially learning and perpetuating social biases found in the scraped texts. This makes understanding of the data sources even more crucial.
Purpose
Bring transparency to the systemic properties of the AI models by developing an Open Ethics Data “Passport” (OEDP). The Data Passport has a purpose at depicting the origins of the training datasets by bringing a standardized approach to convey information about data annotation processes, data labelers profiles, and correct scoping of the labeler’s job.
The project scope document and the code is available on GitHub