Open Ethics Label: AI nutrition labels
Open Ethics Label (OEL) is a “nutrition label” for digital products, including AI systems. It brings standard of self-disclosure to digital products to make these products transparent and safe for consumers.
Generate Open Ethics Label Disclosure Guide PDF Contribute on GitHub
Why labeling?
To explore the concept of self-disclosure, let’s bring the analogy from the food industry. The reason why we can make informed choices about food is because we have a common way to “speak” about food nutrition facts. We all consume food and we’ve used to know what’s inside the package. Proteins. Fats. Carbs… We’ve even got recycling labels printed on the package. But what about data and decision tech? Do we know what’s inside? The tool we’ve got today is called Privacy Policy pages, but they are long, complex and no one reads them.
What is the Open Ethics Label?
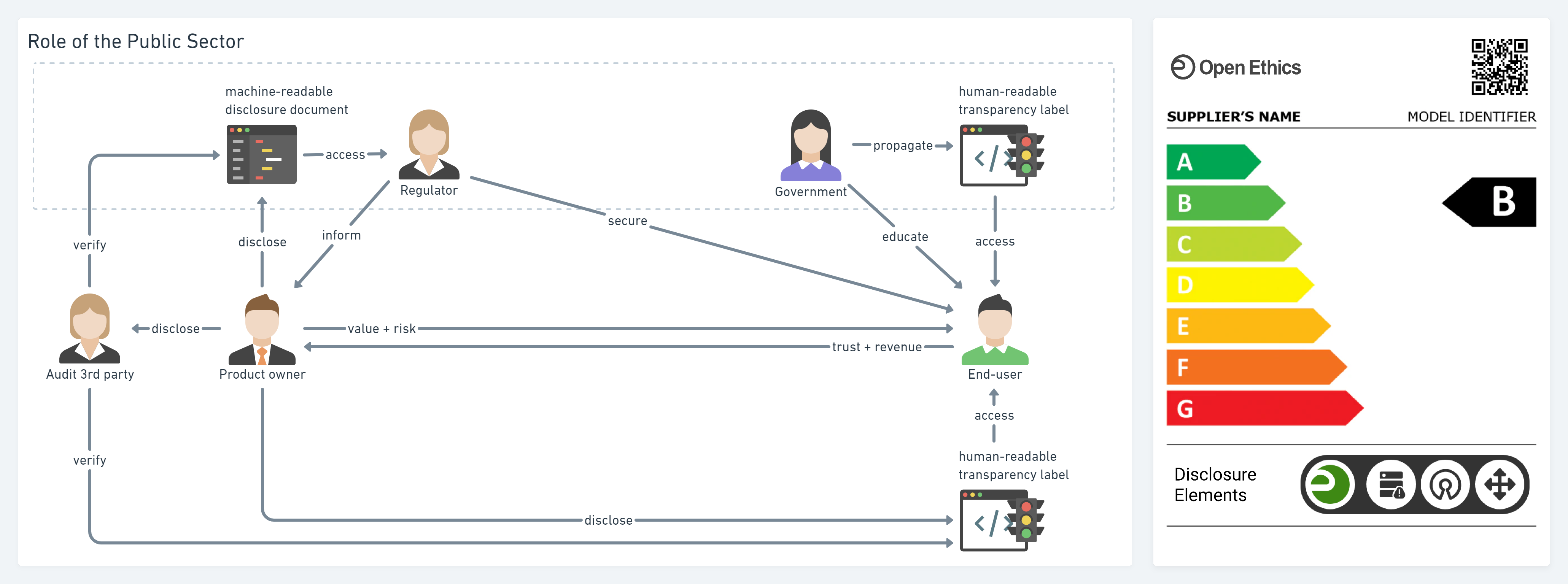
Open Ethics Label is among the first levels of Open Ethics Maturity Model (OEMM), aimed to provide information about your solution to bring transparency and gain trust with your users.
Open Ethics Label (OEL) is not a regular label. The main goal of the OEL is to signify the commitment of the product owner to transparency in front of its users. OEL is the direct and verifiable reflection of what was made public in the process of self-disclosure and it includes details such as approach to algorithmic and data transparency as well as safety precautions when it comes to modulating the system’s output.
In accordance with EU Comission’s white paper framing an “Ecosystem of Trust”, Open Ethics Label is proposing an answer to the Requirement 5.G. “Voluntary labelling for no-high risk ai applications”.
Under the scheme, interested economic operators that are not covered by the mandatory requirements could decide to make themselves subject, on a voluntary basis, either to those requirements or to a specific set of similar requirements especially established for the purposes of the voluntary scheme. The economic operators concerned would then be awarded a quality label for their AI applications. White Paper on Artificial Intelligence: a European approach to excellence and trust
What is it for?
The wizzard allows developer and/or product owner of an AI system to disclose their solution by voluntarily providing information about the three key pillars: Training Data, Algorithms, and the Decision Space. The automatically-generated label HTML code could be then pasted into a website with zero effort, providing transparency to the end-users.
How does it look like?
How does it work?
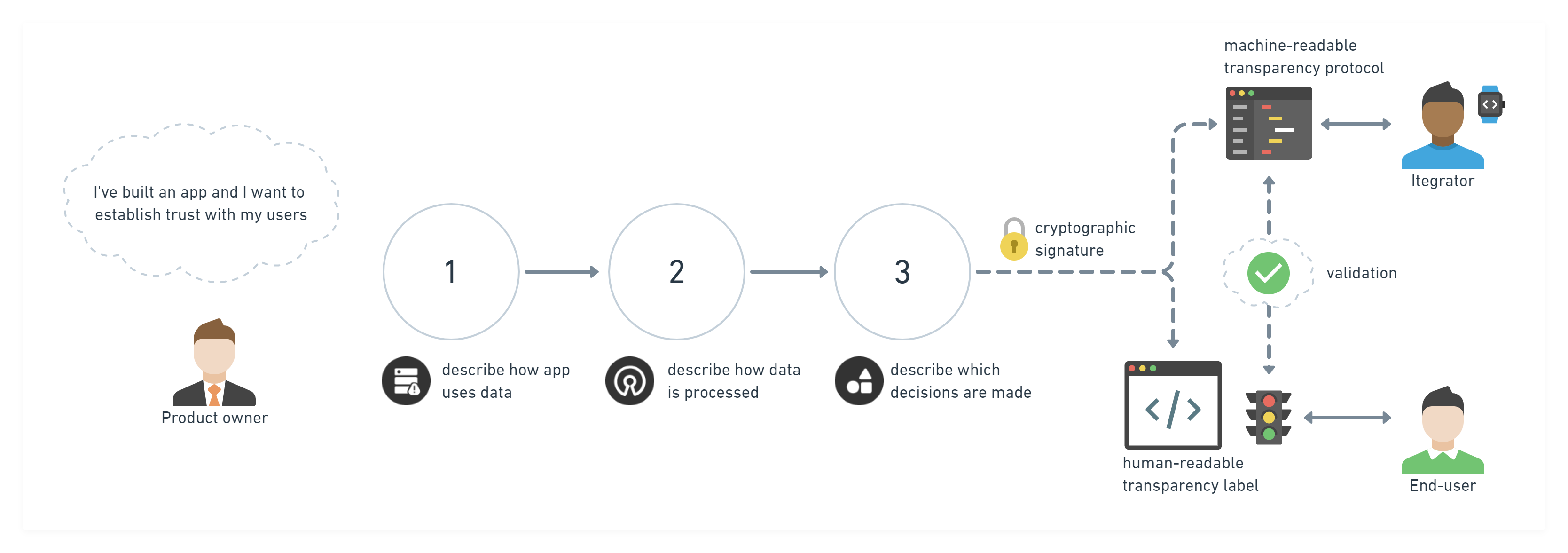
- Product owner submits the form, describing Training Data, Algorithms, and the Decision Space;
- Open Ethics receives the submission and adds a timestamp to it;
- Open Ethics issues a SHA3-512 cryptographic signature on submitted data;
- Open Ethics generates a machine-readable JSON file of Open Ethics Transparency Protocol;
- Open Ethics generates embeddable HTML code with the Open Ethics Label;
- Product owner pastes the HTML code of the Open Ethics Label on his product’s website;
- Users get visual information about any AI system from the labels icons
What are the basic elements of disclosure?
Training Data

Machines learn from data. They find relationships, develop understanding, make decisions, and evaluate their confidence from the training data they’re given. And the better the training data is, the better the machine learning model performs. Providing information about sources of your data may help to identify possible inherent bias and make sure the model is used within its scope of application. When choices are made based on rules or any heuristic, disclosing it can help spot possible problems on the go.
Source Code

Source code can be proprietary or open, and licensing agreements often reflect this distinction. Access to source code allows programmers and skilled users to contribute to the solution. Providing information about algorithmic choices is a way to evaluate privacy and security risks associated with the application logic.
Decision Space

The decision space is the set of all possible decisions that the system can make. Disclosing the decision space is about setting expectations, so that each actor knows what to expect. Providing information about typology of decisions/solutions allows to ensure robustness and safety for complex solutions which involve chaining of multiple software vendors, including the ones providing machine-learning-based products.
Ecosystem Partners



